In the previous blog post we created a database in our Azure Data Explorer (ADX) cluster.
In this blog post we will discuss how we can ingest data into that database as part of this process:

There are several ways to ingest data – we will be using the cluster we have built – but I will cover a FREE method where you can use Azure Data Explorer and familiarise yourself with it – where you only need a Microsoft account or an Azure Active Directory user ID – no Azure subscription or credit card is needed. More on that later.
Data ingestion is the process used to load data records from one or more sources into a table in Azure Data Explorer. Once ingested, the data becomes available for query.
The diagram below shows the end-to-end flow for working in Azure Data Explorer and shows different ingestion methods:
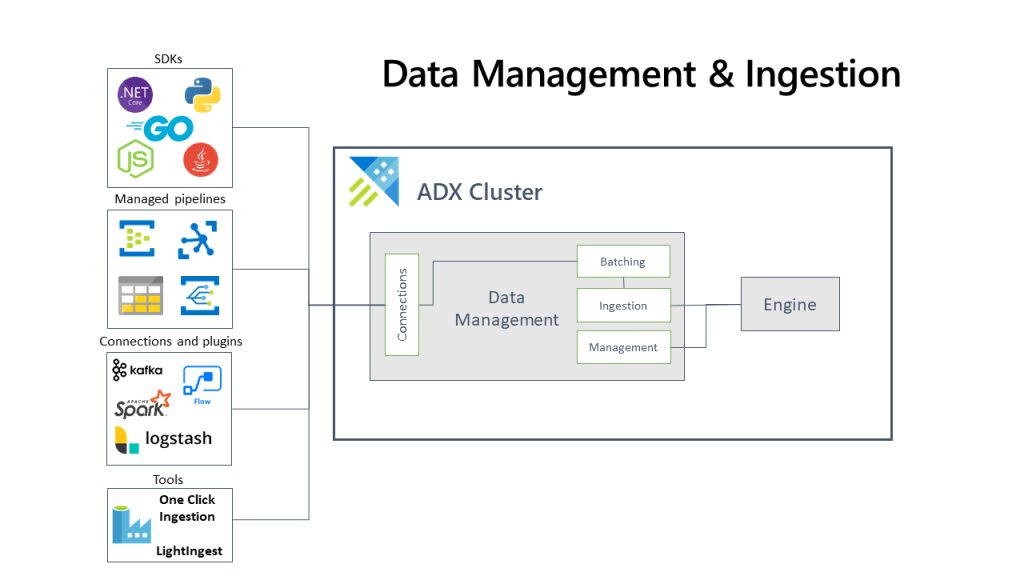
The Azure Data Explorer data management service, which manages the data ingestion, implements the following process:
Azure Data Explorer pulls data from our declared external source and reads requests from a pending Azure queue.
Data is batched or streamed to the Data Manager.
Batch data flowing to the same database and table is optimised for fast and efficient ingestion.
Azure Data Explorer will validate initial data and will convert the format of that data if required.
Further data manipulation includes matching schema, organising, indexing, encoding and data compression.
Data is persisted in storage according to the set retention policy.
The Data Manager then commits the data ingest into the engine, where can now query it.
Supported data formats, properties, and permissions
- Supported data formats: The data formats that Azure Data Explorer can understand and ingest natively (for example Parquet, JSON)
- Ingestion properties: The properties that affect how the data will be ingested (for example, tagging, mapping, creation time).
- Permissions: To ingest data, the process requires database ingestor level permissions. Other actions, such as query, may require database admin, database user, or table admin permissions.
We have 2 modes of ingestion:
BATCH INGESTION:
This is where we batch up our data and we optimise it for high throughput. Out of the two methods this one is the faster method and typical for what you will do for data ingestion.We set our ingestion properties for how our data is batched and then small batches of data are merged and optimised for fast query results.
By default, the maximum batching value is 5 minutes, 1000 items, or a total size of 1 GB. The data size limit for a batch ingestion command is 6 GB.
More details can be found here: Ingestion Batching Policy
STREAMING INGESTION:
This is where our data ingestion is from a streaming source and is ongoing. This allows us near real-time latency for any small sets of data that we in our table(s). Data is initially ingested to row store and then moved to column store extents.
You can also ingest streaming data using data pipelines or one of the Azure Data Explorer client libraries:
https://learn.microsoft.com/en-us/azure/data-explorer/kusto/api/client-libraries
For a list of data connectors, see Data connectors overview.
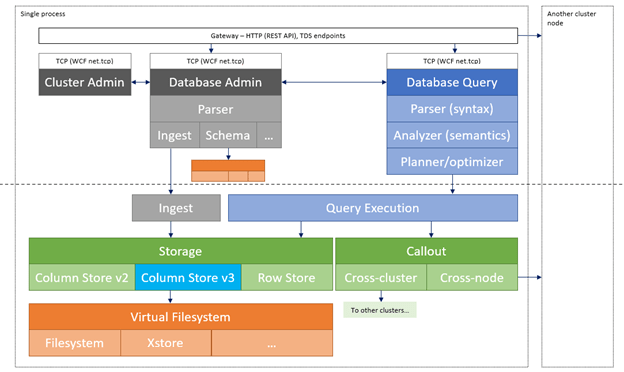
Architecture of Azure Data Explorer ingestion:
Using managed pipelines for ingestion:
There are a number of pipelines that we can use within Azure for data ingestion:
- Event Grid: A pipeline that listens to Azure storage, and updates Azure Data Explorer to pull information when subscribed events occur. For more information, see Ingest Azure Blobs into Azure Data Explorer.
- Event Hub: A pipeline that transfers events from services to Azure Data Explorer. For more information, see Ingest data from event hub into Azure Data Explorer.
- IoT Hub: A pipeline that is used for the transfer of data from supported IoT devices to Azure Data Explorer. For more information, see Ingest from IoT Hub.
- Azure Data Factory (ADF): A fully managed data integration service for analytic workloads in Azure. Azure Data Factory connects with over 90 supported sources to provide efficient and resilient data transfer. ADF prepares, transforms, and enriches data to give insights that can be monitored in different kinds of ways. This service can be used as a one-time solution, on a periodic timeline, or triggered by specific events.
- Integrate Azure Data Explorer with Azure Data Factory.
- Use Azure Data Factory to copy data from supported sources to Azure Data Explorer.
- Copy in bulk from a database to Azure Data Explorer by using the Azure Data Factory template.
- Use Azure Data Factory command activity to run Azure Data Explorer control commands.
Using connectors and plugins for ingesting data:
- Logstash plugin, see Ingest data from Logstash to Azure Data Explorer.
- Kafka connector, see Ingest data from Kafka into Azure Data Explorer.
- Power Automate: An automated workflow pipeline to Azure Data Explorer. Power Automatecan be used to execute a query and do preset actions using the query results as a trigger. See Azure Data Explorer connector to Power Automate (Preview).
- Apache Spark connector: An open-source project that can run on any Spark cluster. It implements data source and data sink for moving data across Azure Data Explorer and Spark clusters. You can build fast and scalable applications targeting data-driven scenarios. See Azure Data Explorer Connector for Apache Spark.
Using SDKs to programmatically ingest data:
We have a number of SDKs that we can use for both query and data ingestion.
You can check out these SDK and open source projects:
What we will look at next is the tools that we can use to ingest our data.
