![tsql2sday150x150-1[1]](https://hybriddbablog.com/wp-content/uploads/2017/05/tsql2sday150x150-11.jpg?w=94&h=94)
This blog post is part of T-SQL Tuesday #90 – Shipping Database Changes .
I have decided to write about a client’s SQL Server based system that was having issues with deployment of code changes. The code changes were being deployed by a third party contractor.
The client engaged with the company I work for to see if we could help out as we were deploying to their other systems with zero issues in PROD.
The issues they were experiencing with the other contractor were:
- error prone manual deploys to PROD
- no UAT or QA systems so effectively deploying straight from DEV to PROD.
- little testing and what testing there was — manual and laborious
- no source control of database changes
- no central repository (or consistency) of configuration settings
- deploy outages that were 4 hours long
So rather than a greenfields project where we can do anything and everything with Continuous Integration and Continuous Delivery we were going to back fill these against a running PROD system – carefully.
So this is what is termed as ‘brownfield’ – a running legacy system…
We worked with the 3rd party contractor as they too were having issues as their DBAs were working at 3am until 7am and it wasn’t a great time.
Note: we were not replacing the 3rd party contractor – we were helping everyone involved. The particular client was very important to us and we were happy to help them out across their other systems we did not actively manage (yet).
The first step was to introduce Source Control and Continuous Integration – so all code that was being developed was pushed up to Source Control. For ease of use and to prove that this was a good thing we started with the application code.
Builds were kicked off in Team City and a consistent artifact was created, we also introduced automated testing.
We then retrofitted consistent environments to the application lifecycle – how’d we do the database side?
We used the Data Tier Application (DAC) model of creating an entity that contains all of the database and instance objects used by an application. So we generated a DAC out of the PROD system (of just the objects and schema definitions – NOT the data), stored it in Source Control and used sqlpackage to create 5 databases that were all standard (compared to PROD).
They were:
CI, QA, Integration, UAT, prePROD
CI – was there to test every build generated against.
QA — was there for nominated QA engineers to test functionality against
Integration – was there for Integration testing with certain backend/frontend systems
UAT – was there for User Acceptance Testing
prePROD – was there for a true copy of PROD
prePROD was a special case as this was a full replica of PROD but with scrambled data.
The application tier was standardised according to my OCD like naming scheme – see my post here about why this was a good thing.
By then making the 3rd party developers push all application & database code changes to source control we then had a versioned state of what changes would be made.
This wasn’t a “hit the GO button” scenario — we had to try things out manually and carefully and there were things that went bump. BUT they went bump in CI and Integration and even prePROD – but by following Continuous Delivery principles and applying to them to the database we have in the past two years never gone bump in PROD.
Now we couldn’t do all the things we wanted – this was not a greenfields project. So here is what we compromised on:
We had to use invoke-sqlcmd for deploying the changes against the databases.
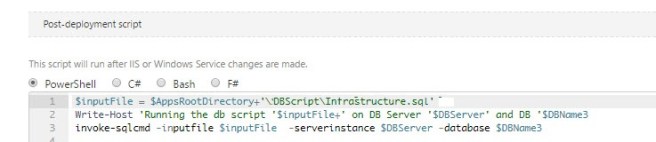
This was OK – because we using a variablised script (which the 3rd party contractor had never done before so we showed them how) and it was deployed consistently across all databases — any issues we caught early on.
Also our deployment process step:
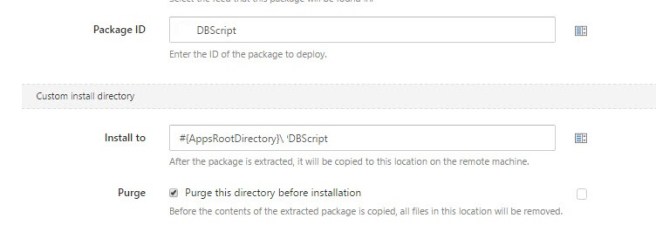
was standard across all environments in our database/application deployment lifecycle.
Here is what the standardised packages from the Continuous Integrationbuild looked like:
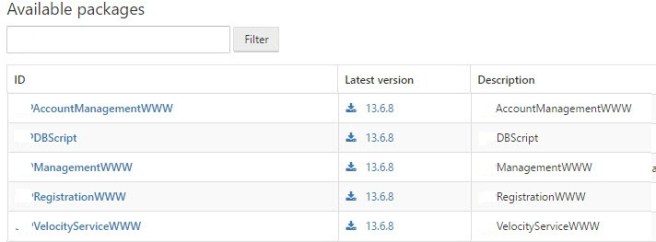
The best part was that ALL database changes in the DBScript package were in the same version as associated application changes. In fact we also included any configuration changes in the repo as well – you know Infrastructure as Code type stuff.
So let’s measure how the changes are against the initial issues:
error prone manual deploys to PRODThe deploys were automated and any errors were caught early
no UAT or QA systems so effectively deploying straight from DEV to PROD.
We had PROD-like environment that could give us feedback immdiately and protect PROD from out of process changes.little testing and what testing there was — manual and laborious
Introducing both automated tests in the Continuous Integration build steps and automating the deployno source control of database changes
All database changes were pushed up to source control and were versioned.no central repository (or consistency) of configuration settings
All configuration settings were stored in a central reposistory and deployed out as aprt of Continuous Delivery processes. Everything was a variable and consistent across the whole application/database lifecycledeploy outages that were4 hours long
Deploys were now around 5 minutes as everything was consistent and proven and we never rolled back once. We could if we wanted to – but didn’t need to.
The upshot of using Continuous Delivery for their ‘brownfield’ system was that database & application changes were consistent, reliable and automated.
The client was very happy, the 3rd party contractor was very happy too (as their time-in-lieu, angst was reduced) and the client approached us to manage more of their systems.
For more things like this — go read the other posts about this month’s T-SQL Tuesday
Yip.
.