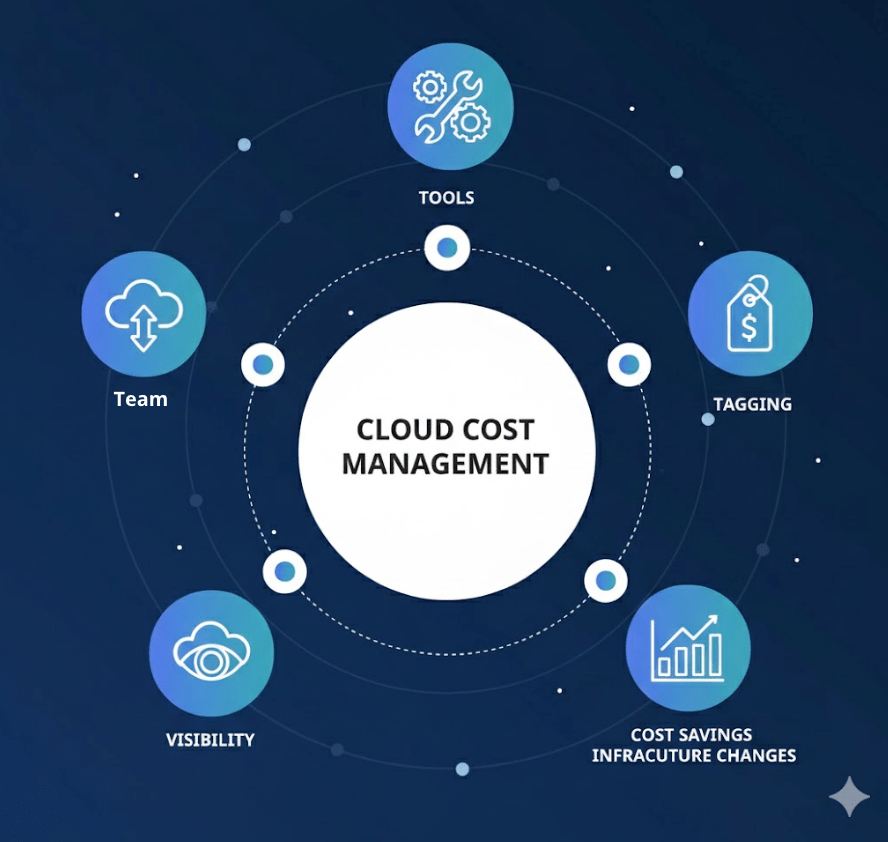
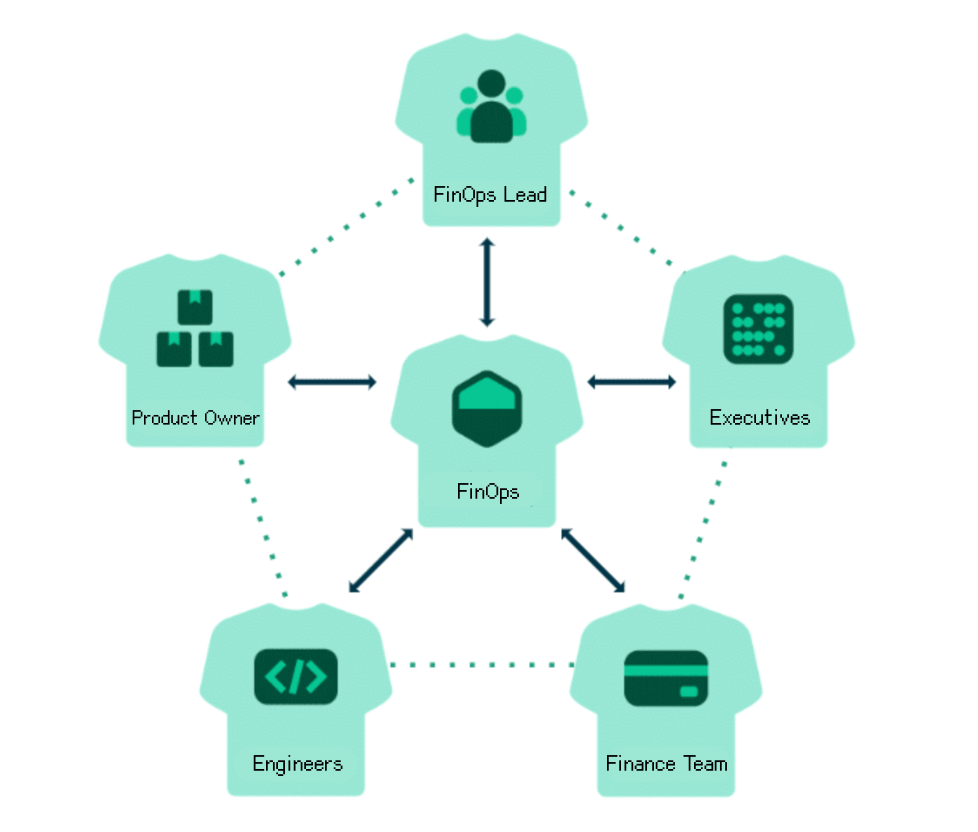
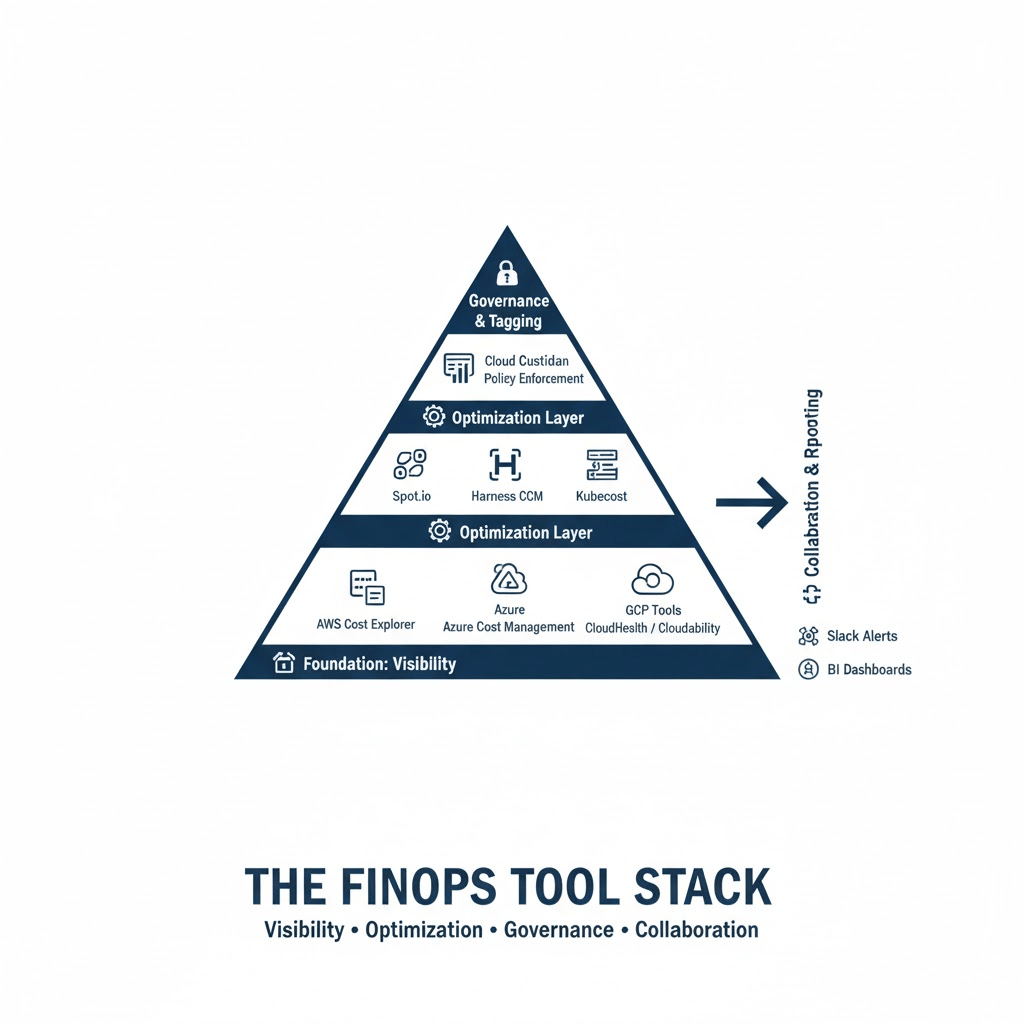
DevOps is about shortening the system development lifecycle. Plan faster, build faster, test faster, deploy faster. But while we accelerate delivery, why not shorten the expense lifecycle as well? Every deployment consumes compute, every environment uses storage, and every scaling rule involves cost. Speed and spend are linked and move together.
If we’re eliminating inefficiency in delivery, it only makes sense to tackle inefficiency in spending too. This is where DevOps and FinOps are best mates.
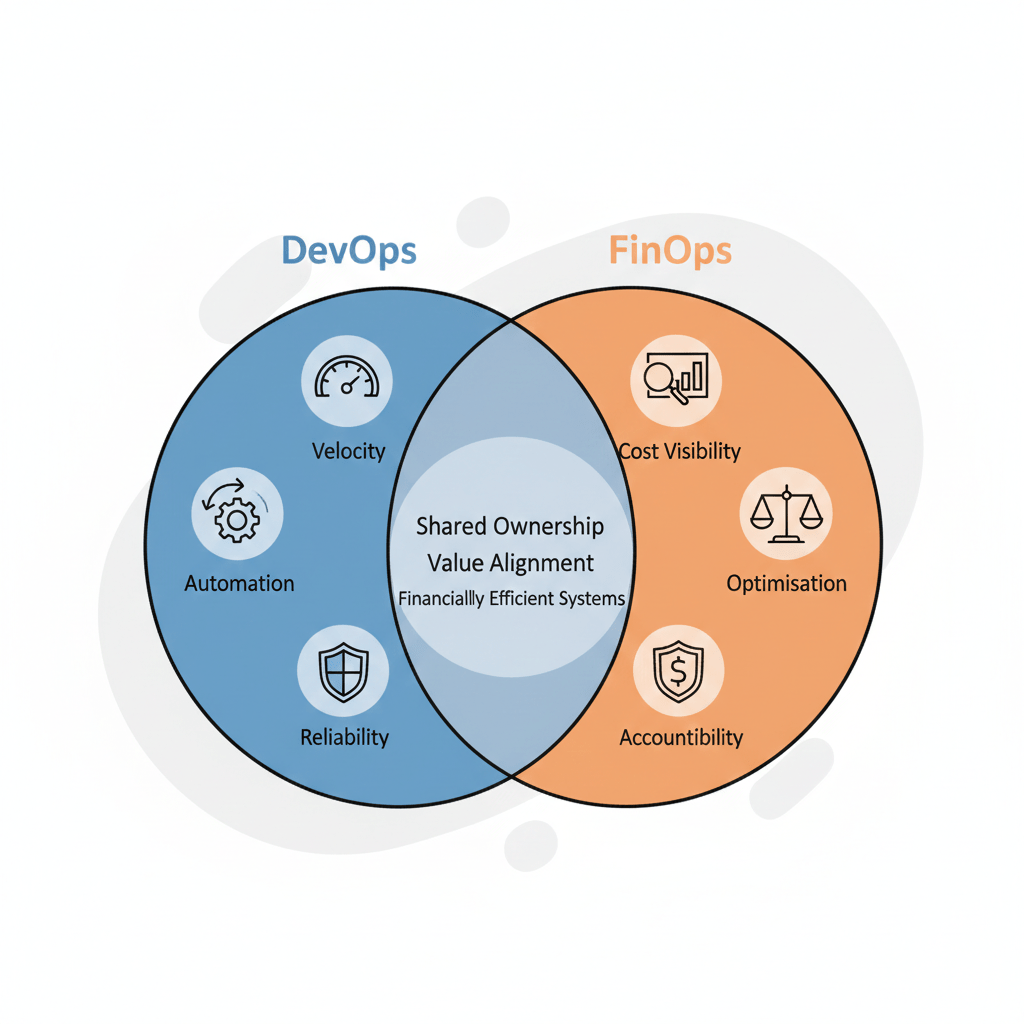
DevOps Accelerates. FinOps Optimises.
DevOps removes software inefficiencies, FinOps removes financial waste. DevOps focuses on velocity, reliability, and smooth delivery through automation and collaboration. FinOps adds another layer of discipline, and it does not slow teams down. It ensures that hard-earned velocity doesn’t turn into uncontrolled spending. Acceleration without optimisation increases risk, and optimisation without acceleration limits innovation.
Cost is a System Metric
We already treat latency, uptime, and deployment frequency as indicators of system health, and costs deserve the same respect. Infrastructure sizing, storage strategies, and scaling configurations also carry financial weight. When cost is part of the observable system metrics, engineers start thinking in a more complete way. Decisions are more than just about speed or performance; they’re about delivering value efficiently. This approach strengthens innovation, ensuring systems are both fast and financially responsible.
The Real Intersection
The true intersection between DevOps and FinOps lies in shared ownership. DevOps processes own how systems are built and delivered, and FinOps practices ensure those systems operate with financial clarity and control. They connect engineering execution directly to business sustainability. This integration transforms cloud operations from reactive cost management to proactive optimisation. Instead of discovering inefficiencies after billing cycles close, teams gain continuous insight into the financial impact of their decisions.
Conclusion
Shortening the development lifecycle improves time to market. Shortening the expense lifecycle improves operational efficiency. Organisations that integrate both build systems that are scalable, reliable, and economically sustainable. The smartest engineering teams treat speed and cost as inseparable metrics: the true measure of cloud maturity.
Yip.