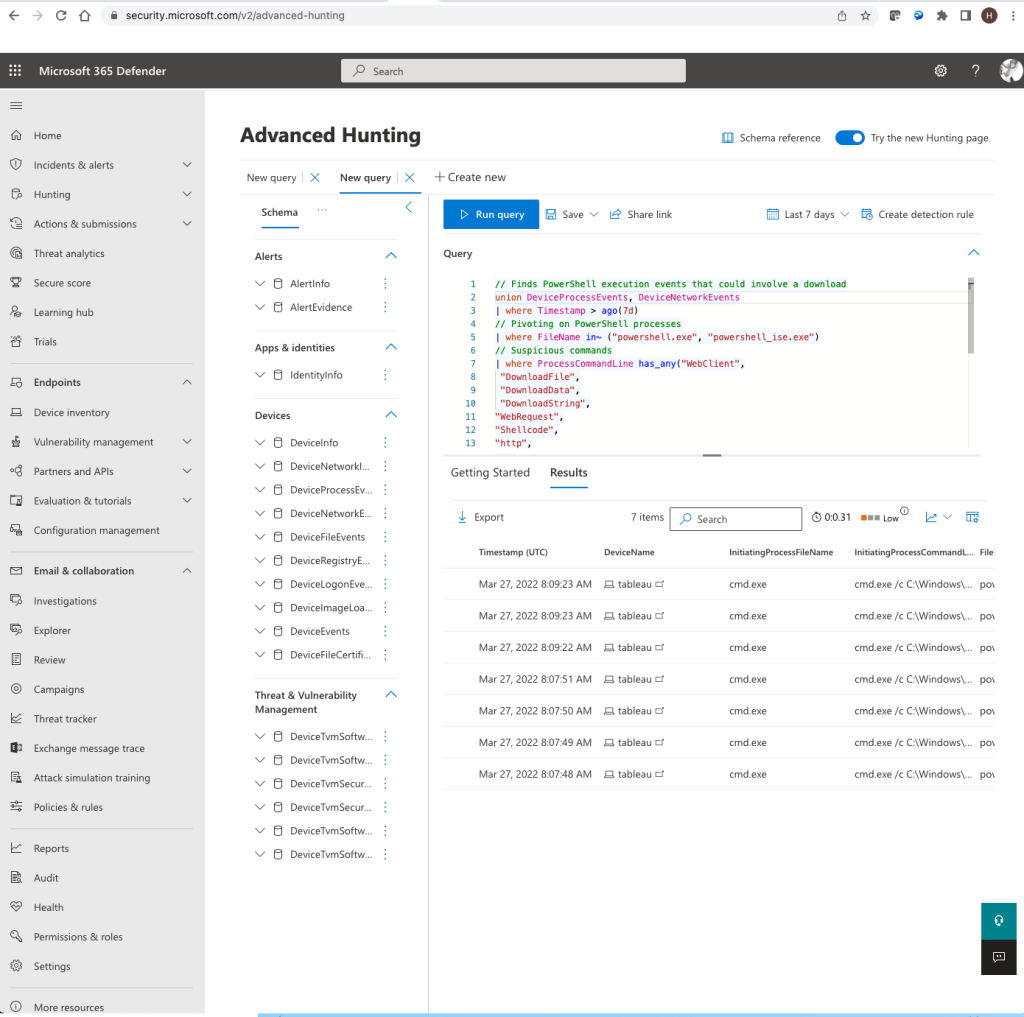
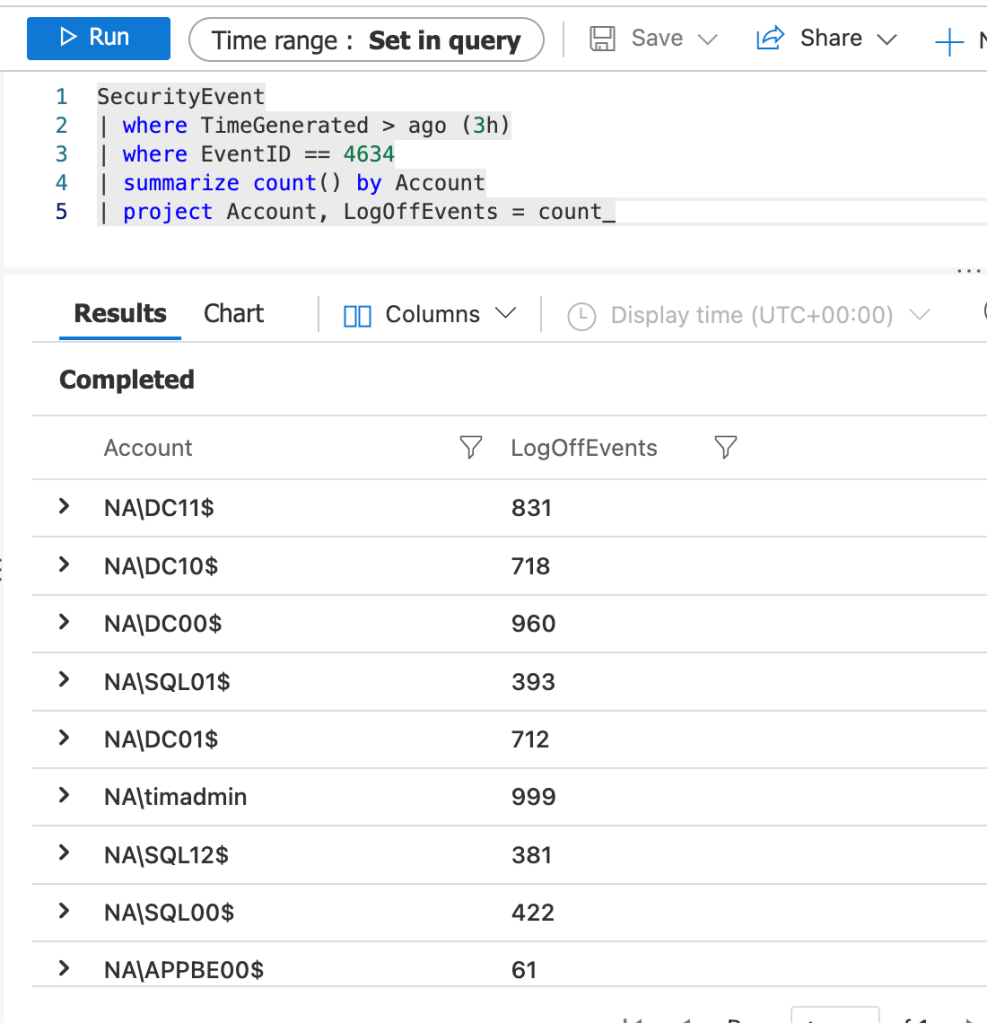
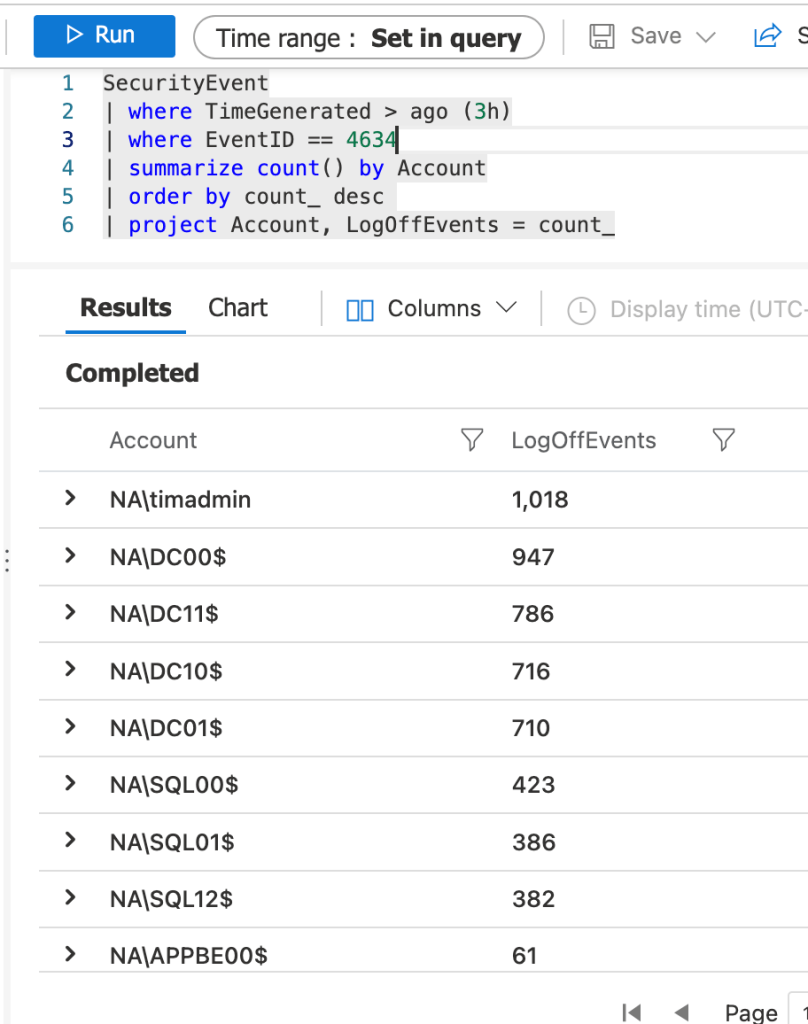
This blog post is based on my personal experience running an Azure Data Explorer (ADX) cluster.
I was doing a presentation for Data Platform Summit in India, I spun up my cluster, created database/tables, ingested data and forgot to tear down the cluster.
I also scaled it right up to show how we can make things go faster…
…when we scale things in Azure – it costs more!!
I burned through my monthly MSDN subscription allowance in 2 days…
So here are a couple of ways you can not waste money with cloud resources.
- Learn Infrastructure as Code…
I use terraform on an hourly basis and so my first go to is spin it up, ingest data, use it then tear it down.
When I need the cluster again – just run my script:
resource "azurerm_resource_group" "rg" {
name = "my-kusto-rg"
location = "Australia East"
}
resource "azurerm_kusto_cluster" "cluster" {
name = "kustocluster"
location = azurerm_resource_group.rg.location
resource_group_name = azurerm_resource_group.rg.name
sku {
name = "Standard_D13_v2"
capacity = 2
}
}
resource "azurerm_kusto_database" "database" {
name = "my-kusto-database"
resource_group_name = azurerm_resource_group.rg.name
location = azurerm_resource_group.rg.location
cluster_name = azurerm_kusto_cluster.cluster.name
hot_cache_period = "P7D"
soft_delete_period = "P31D"
}
- Stop your cluster when not in use:
To stop the cluster, at the top of the Overview tab, select Stop.

- To restart the cluster, at the top of the Overview tab, select Start.
When the cluster is restarted, it takes about 10 minutes for it to become available (like when it was originally provisioned).
It takes more time for data to load into the hot cache.
Unless you absolutely do need to have the cluster around my recommendation is to use Infrastructure as Code to spin it up as you need it then destroy it. Because as much as I love Azure – I also love saving my own and client money…
#Yip.