This blog post is a form of resolution to the issue of not being able to shrink a transaction log after a FULL backup where you this error:
“Could not locate file ‘xxx_Log’ for database ‘xxx’ in sys.database_files ”
Its funny how peculiar issues decide to crop up on a Friday afternoon…
…just as you’re about to go home.
Long story short a client’s database transaction log kept growing and they couldn’t truncate it and they needed it to be shrunk. So I was asked to assist.
My quick and dirty method was to shrink the 500GB file down to 1GB:
USE [master]
GO
ALTER DATABASE [clientTdatawarehouse] SET RECOVERY SIMPLE WITH NO_WAIT
GO
USE [clientTdatawarehouse]
GO
DBCC SHRINKFILE (clientTDataWarehouse_log, 1024)
GO
USE [master]
GO
ALTER DATABASE [clientTdatawarehouse] SET RECOVERY FULL WITH NO_WAIT
GO
However I got this error:
Msg 8985, Level 16, State 1, Line 1
Could not locate file ‘clientTDataWarehouse_log’ for database ‘clientTdatawarehouse’ in sys.database_files. The file either does not exist, or was dropped.
Hmmmm……
So I ran
use [clientTdatawarehouse]
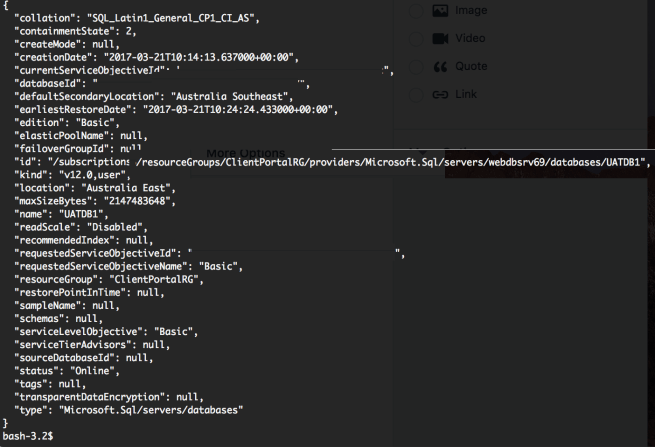
SELECT name FROM sys.database_files
I also ran
use [clientTdatawarehouse]
exec sp_helpfile
And both times got back what I’d expect:
name
clientTDataWarehouse
clientTDataWarehouse_log
But no matter how I copied and pasted it into the original query – I still got the error.
I tried everything listed here:
http://dba.stackexchange.com/questions/43932/dbcc-shrinkfile-works-with-file-id-but-not-with-logical-name
and
http://stackoverflow.com/questions/12644312/could-not-locate-file-mydatabase-for-database-mydatabase-in-sys-database
But still got the weird error.
This was a database that COULD back itself up normally – both bak and trn type backup..!!
(the reason I got called in was because the log and backup drive was very full — because the transaction log kept growing and they couldn’t shrink it and….)
So I decided to clear some disk space, do a backup and then tried this:
USE [clientTdatawarehouse];
ALTER DATABASE clientTdatawarehouse MODIFY FILE
(NAME = clientTdatawarehouse _log, NEWNAME = clientTdatawarehouse_log_1);
It worked in the rename part and now for the shrink part.
Original script slightly modified:
USE [master]
GO
ALTER DATABASE [clientTdatawarehouse] SET RECOVERY SIMPLE WITH NO_WAIT
GO
USE [clientTdatawarehouse]
GO
DBCC SHRINKFILE (clientTDataWarehouse_log_1, 1024)
GO
USE [master]
GO
ALTER DATABASE [clientTdatawarehouse] SET RECOVERY FULL WITH NO_WAIT
GO
It worked!!
Renaming the logical name back to the original also worked and I could shrink the transaction log. BTW I should state the shrinking transaction logs is not a good thing but this client does it (for reasons) – oh well.
As to why SQL Server had forgotten what the name is – that is my weekends project of diagnosing it. For now – the database can be backed up, the client is happy and my Friday is now my own…
..after going back and contributing back to the community by updating the two sites I initially looked at.
Yip.