SQL Saturday conferences are awesome.
That is the opening line of this blog post – because it’s true and understated.
If you’re reading this and do not know what a SQL Saturday is – go visit http://www.sqlsaturday.com/ and find your nearest SQL Saturday. I’ve been lucky enough to have gone to a few as an attendee and now I go as a speaker around Australasia and Portland, Oregon.
The tl;dr of this can be found in the summary section – it’s a summary of how I found some ways to grow the attendance of my SQL Saturday.
Anyways, if you’re keen to read on:
My experience with SQL Saturday in Christchurch, NZ has been:
2013 Attendee
2014 Attendee, volunteer
2015 Attendee, volunteer, committee member
2016 Attendee, volunteer, speaker, co-organiser
2017 Attendee, volunteer, speaker, lead organiser
Martin Catherall (t | b ) had done a fantastic job of introducing SQL Saturday to Christchurch and in 2016 we worked together to make SQL Saturday Christchurch to become SQL Saturday South Island. Why South Island – well the fact is that New Zealand is small. Beautiful and awesome, but still small. Christchurch only has 366,000 people and all of the South Island — 1,096,200 people.
To grow our attendance numbers we had to include our ‘sister’ cities.
Thus SQL Saturday South Island was born in 2016 – this was also the FIRST year we hadn’t piggy backed off the local Code Camp Conference (which I am part of an awesome triumvirate with Steve Knutson (t | b) & David Carter (t | w) ).
We had 123 attendees in 2016. This was honestly 22 more people than what I said to Martin that we had to achieve.
Fast forward (or rather catch up) to 2017. Martin very graciously let me take the lead on SQL Saturday South Island 2017 (#614) — mostly because he now lives in Melbourne, Australia — he moved there in October 2015.
My aim was 150 registrations. Which I thought was a ridiculous (for many reasons I never said this to Martin) number. The 123 registrations in 2016 was mostly because we were extremely lucky to have John Martin (t | b) from SentryOne come over. A speaker from the UK of John’s calibre will bring in a good crowd – and did.
For SQL Saturday you need a couple of things:
Venue
Speakers
Sponsors
Attendees
In my opinion that list is from easiest to hardest.
The venue is fairly easy because at worst – you pay for a venue. There’s always a venue…
I am now a speaker on the SQL Saturday ‘circuit’, so I know that I can promote how good Christchurch is to entice International speakers – and I did. I managed to get my SQL bro Nagaraj Venkatesan (t ) from Singapore to come over – I offered a room in my house to help him save costs. This guy is one of the most nicest guys we have in the speaker community – which is why I consider him a ‘bro’ (kiwi speak for brother).
Sponsors – a little trickier as there is only a finite amount of money to go around and NZ’s population size is 4.5 million. Only slightly larger than Sydney or Melbourne Australia. As mentioned Christchurch is tiny compared to the bigger cities that do SQL Saturday in Australasia. So far I’ve never had a sponsor say no that we’ve approached and we’ve also been lucky to have some approach us. I love numbers so I always talk about how our SQL Saturday has grown over the years – as well as the SQL Server User Group I run that grew from 20 users in 2013 to 458 in 2017. Why mention the User Group? — well it’s going to feed the SQL Saturday with people.
Sponsors love people.
I’m lucky/blessed/fortunate that Jade Software – the company that employs me has been generous to us over the years and has supported us greatly.
(Thank you Caroline Francis our Director of Marketing for always reading my emails that contain lots of numbers and heaps of enthusiasm…
… and agreeing to help us out with X, Y and Z)
Which after this long intro – leads me to the point of this blog – how to get more attendees along to SQL Saturday or any Data Platform conference.
Marketing the conference requires getting the information out to the masses.
Because I was locally based I took this as my responsibility.
I offered to speak at as many local User Groups that were applicable (I really can’t write/do java so had to scrub that UG off my list).
After each presentation I had a slide or the website that I quickly talked about SQL Saturday South Island. When I took over the SQL Server User Group in October 2015 one thing I decided to bring to it was collaborative community — I invited all the User group leaders and their respective groups to Christmas Drinks – and started the idea of cross-talks. I’d speak at the .NET UG about data – the .NET speakers could speak at my UG about accessing data. I even had the Agile Group join my group for a session from RayGun.
(If you haven’t looked at RayGun and you do any form of development – you need to)
So this collaborative community meant that instead of just my own User Group attendees I now had a far greater reach. I emailed a lot of User Group leaders and asked them to email their groups about SQL Saturday (I wrote the text that they could just copy|paste – vitally important that you make it easy…!!).
I lecture at a local university – 3 times a year – however my first lecture was in May.
So I drove in one Monday morning in my own time and spoke to the class – I had the slides promoting topics (Machine Learning, Cognitive Analysis, SQL injections) and website and got my SQL Saturday registration site listed on their internal intranet.
We run tech events in Christchurch – I went to a number of applicable ones, because I’ve spoken at a few – I approached the people in charge of mail outs and gave them information that they could put out to their mailing lists here in Christchurch (again make it simple for them – copy|paste for them takes 5 seconds!!).
I asked my mates on the Twitter to retweet anything I put up about #sqlsat614 I even asked people who use Facebook to promote us. I don’t use Facebook like normal people so my reach there was very limited.
A special mention goes to Nick Draper (t ) – one of my User Group committee members and who has been co-running it since it began officially in March 2013. Nick used his own network of people within Microsoft and the Christchurch IT community to help promote the event. It is people like Nick and everyone I mention in this post who make a HUGE difference and make my job so much easier.
I used LinkedIn as a method of getting the message of a FREE conference that will help you learn as a way of getting interest. I used my own network to like/comment/share/write their own pieces. I made sure the words “free education event” were included. Where people wrote on LinkedIn I purposely did NOT give them text to write – this was a personal writing and if they chose to support me then I’d rather it were their words. Plus I take 2,183 words whereas others take 200 words to get a message across…
Because I co-run Code Camp as well – it meant I had (limited) access to email addresses. So I signed up with mail chimp and sent a nice email to 284 people who had attended in the past 4 years (I only sent one email out as I felt quite ‘spammy‘ doing it – even though it was for a good cause).
I also TIMED all of the above events so that we started small with one thing, then hit the population with another social media interaction. I did not want to over saturate and anger my audience with spam. By drip feeding over 6 weeks I watched the numbers rise:
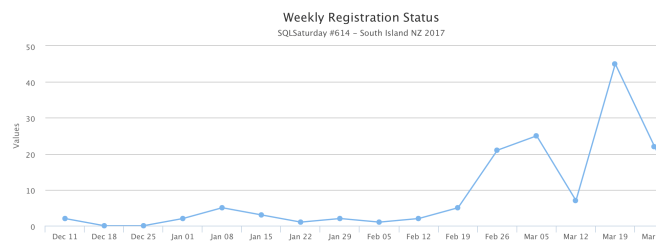
I had done some initial “coming soon” announcements in early January which is why there were some initial registrations then.
Timing is vitally important here – announce too soon and people forget – announce too late and people have plans. It is on a Saturday after all.
Saturday’s are important to our industry – it is the day where we can (hopefully) relax, associate with friends, spend time with family.
I’ve found getting the message out there about 3 months out – just a ‘hey we’re gonna be on this date more news soon’ type of announcement works well. 6-8 weeks out and you’ve got your speakers lined up, you’ve got a venue and you know if you can supply a free lunch and/or something afterwards. Sponsors are truly valuable for allowing us to exist and do things.
I don’t want SQL Saturday South Island to be all flashy, with heaps of shiny things – that isn’t the New Zealand way for one thing and my budget is just right that I know I can put this on at a big enough venue, that people will learn something and there’ll be a free lunch and the possibility of a free beer and pizza afterwards.
Oh yeah – let’s quickly talk about something that is a game changer:
Volunteers
I’ve been one, I still am one and without them — we’d be a mess.
Last year when I took over as co-organiser I let my inner Operations Manager take over and made volunteers an official part of SQL Saturday South Island. Beforehand it’d been mostly informal and it mostly worked.
By making it official in 2016, (2017 is the first year we’ve used the SQL Saturday volunteer portal and I really wish we had earlier) it meant that I knew how many people would help us on the registration table, how many people would help clean up afterwards. Which allowed me to plan and also know how many small thank you gifts I would buy to say a huge thank you to the unsung heroes of SQL Saturday South Island.
Summary
In short these are the things that helped grow SQL Saturday South Island:
- Growing a community locally amongst User Group leaders – SQL Saturdays (or at least mine) are a combination of DEV, DBA, OPs people. This means that the structure of my SQL Saturday will appeal to
- .NET developers
- DBAs
- Data Scientists
- Operations folk who spin up resources.Collaboration goes both ways – I spoke at a lot of local UGs and invited the leaders of them to send speakers my way.
- Local Universities – if you aren’t already – reach out to local universities to:
- teach students about the real world – even just for an hour
- invite said students to come along and learn from the masters of our industry
- Local Tech Events – same thing – go along, speak, support them because:
- you’ve now extended your User Group reach to 100s more professionals
- you’ll network with a few more professionals and learn from them
- they’ll assist you in communicating to their members about SQL Saturday
- Twitter – #sqlpass , #sqlsaturday , #sqlsat , #sqlfamily means:
- you’ll get exposure of your event for speakers/sponsors/attendees
- others who care (and there are a lot who do) will retweet to their networks
- it gives you a chance to work on your own brand (that’s another post….)
- LinkedIn – be careful – this is a professional network and you want to make sure that you’re not over-saturating your network with spam. This was the one area where I let people write their own words. In other areas I provided text to make it easy for people.
- MailChimp – as above – you need to be wary of just spamming your intended audience. I had 62% click rate on my mail out (notice I didn’t write mail outs there). This was primarily an announcement – I timed it for 6 weeks out and left it at that.
- Friends in the industry – one of my User Group committee members works in recruitment. I provided some text and she re-wrote (shortened) it and sent it out to her own mail list. My other industry friends reached out to their contacts i.e. Microsoft to publicise our event via (say) MSDN mail outs.
Even people as far away as Brisbane can help via Social Media like a historical supporter of SQL Saturday South Island – Warwick Rudd (t | b |w)
- That time at a BBQ….. I was at a mates BBQ and (randomly) starting talking about Power BI, a person there actually worked in IT and was interested in learning from Reza Rad (t | b) (he knew of RR but didn’t know of the upcoming SQL Saturday!!). He registered the next day and event registered for Reza’s precon. Basically talk a lot about your event – because your event is AWESOME.
This blog is about growing numbers – we are now at our venue limit of 150 people. My ridiculous number actually came about.
[Update 25th April 2017: Read my post about how well it actually went here]
Vitally important – our number of volunteers grew from 2 of us back in the 2014 to 12 people in 2017.
So SQL Saturday South Island is next weekend on 8th April, I’m really looking forward to it – to see some of my fellow speakers, to learn some things and more importantly to help all the people I’ve been communicating about it over the past 2 months:
connect, share and learn
Yip.